声音
在介绍语音识别技术之前,我们先认真理解一个词”声音”
定义
声音(sound)是由物体振动产生的声波。
声音是通过介质(空气或固体、液体)传播并能被人或动物听觉器官所感知的波动现象。
最初发出振动(震动)的物体叫声源。声音以波的形式振动(震动)传播。声音是声波通过任何物质传播形成的运动。
声音作为一种波,频率在20 Hz~20 kHz之间的声音是可以被人耳识别的。
相关术语
- 周期:声源振动一次所经历的时间,记作T,单位为s。T=1/f
- 频率:赫兹是频率单位,记为Hz,指每秒钟周期性变化的次数。声源在一秒中内振动的次数,记作f。
- 波长:沿声波传播方向,振动一个周期所传播的距离,或在波形上相位相同的相邻两点间距离,记为λ,单位为m。
- 声速:声波每秒在介质中传播的距离,记作c,单位为m/s。声速与传播声音的介质和温度有关。在空气中,声速(c)和温度(t)的关系可简写为:c = 331.4+0.607t 常温下,声速约为345m/s。
- 声强:声强是指单位时间内,声波通过垂直于传播方向单位面积的声能量。单位为 W / m2。对于人耳听觉来说有高低两个阈值,低于小阈值就无法听到,高于大阈值就会使耳朵阵痛。
- 分贝:是用来表示声音强度的单位,记为dB。为什么会有这个单位,因为人们听到的声音,若以声压来表示,变化范围非常大,可以达到六个数量级以上,同时由于人体听觉对声音的刺激不是线性,而是对数比例关系,所以采用dB来表示。公式为:N = 10lg(A1/A0)
- 响度是人的听力感觉产生的术语,是主观上的表示单位。
语音
语音是人的发声器官发出的一种声波. 它具有一定的音色,音调,音强 和音长。
-
音色:也叫音质,是一种声音区别于另一种声音的基本特征。
-
音调:是指声音的高低,它取决于声波的频率。
-
音强:它由声波 的振动幅度决定。
-
音长:它取决于发音时间的长短 。
发音
世界上所有的声音都是物体振动产生的声波在介质中传递的结果,因此声音的产生离不开振动的动力、振动的源头和振动的共鸣腔。
发音器官
人类的发音器官可以分为三大部分:呼吸器官、喉头声带与声腔(口腔、鼻腔与咽腔)。
-
呼吸器官:
呼吸器官主要包括肺、气管和支气管。 -
喉头和声带
喉头由软骨构成,呈圆筒状,上接咽腔,下接气管,喉头的外表就是喉结。 喉头软骨构成的"圆筒"中有一对声带,声带是两片富有弹性的唇性肌肉,其前后两端都粘附在软骨上。 两片声带之间的空隙叫声门,声门可以打开和关闭。从而产生不同的气流状态。 -
声腔
声腔包括口腔、鼻腔和咽腔三部分。
声腔是人类最重要的发音器官,声腔中又以口腔及其中的各种器官作用最大。
发音原理
既然我们知道声带是发音的主要来源,那声带是如何工作的呢?
肺部的收缩和扩张可以产生呼气和吸气的气流变化,这种气流变化不仅为人类的生存提供氧气和二氧化碳的交换,而且为语音的发出提供了振动的动力(世界上多数语言的语音利用呼气作为动力,非洲有些语言还利用吸气发音)。
肺部产生的气流通过声门时,使声带颤动,产生周期性声波,这就是发音最初的基音(后续的基音检测技术就是反向推算出这个频率)。
由于人类的口腔可以变化,以及舌头和软腭可以上下活动,以及一些天生的鼻腔和咽腔影响,使得声腔的形状变化万千,发出种种不同的声音。
从信号与系统的角度理解,就是声带产生了一系列激励信号,经过声腔这个系统函数,最后产生了外界听到的这个响应信号,也就是声音。
发音类型
人类发音过程由三类不同的激励方式,相应的产生三类不同的声音,即 浊音、清音、和爆破音。
浊音:当气流通过声门时声带的张力刚好使声带发生较低频率的张弛振荡,形成准周期性的空气脉冲,这些空气脉冲激励声道发声便产生浊音,比如元音。蚀音的基本频率就是基音频率,
清音:如果声道中某处面积很小,气流高速冲过此处时而产生湍流,当气流速度与横截面积之比大于某个门限时便产生摩擦音也就是清音,比如辅音 s, sh, f等。
爆破音:如果声道某处完全闭合建立起气压,然后突然释放而产生的声音就是爆破音,如塞音 p, t,k 等
发音特性
通过对语音信号特性的分析表明,浊音语音的频谱一般在4KHz 以上便迅速下降。而清音语音信号的频谱在4KHz 以上频段反而呈上升趋势,甚至超过了8KHz 以后仍没有明显下降的苗头。如下我录音的”qi”的频谱图。
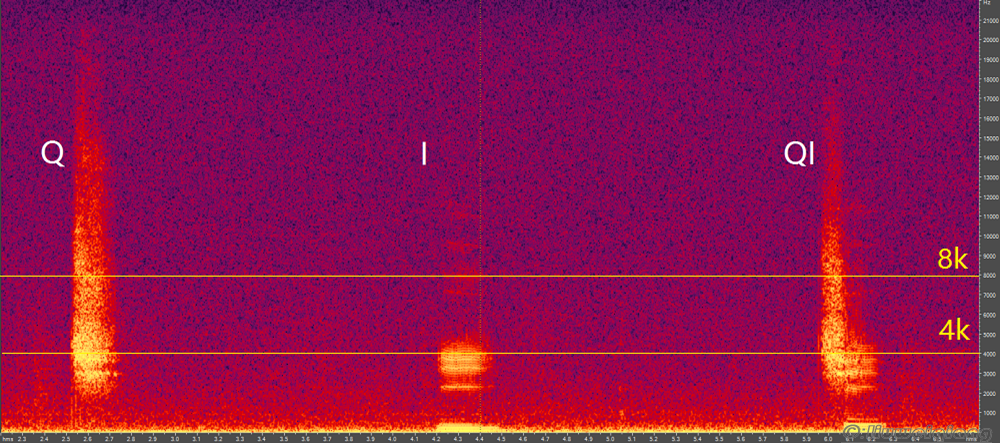
汉语单元
在语音识别系统中,声音信号会被逐级切割来分析。
在汉语中切割顺序就是从语句-词语-音节-音素
音节是用听觉可以区分清楚的语音基本单位,它的构成分头腹尾三部分,因而音节之间具有明显可感知的界限。在汉语中一般一个汉字的读音即为一个音节。
音素(phone),是语音中的最小的单位,依据音节里的发音动作来分析,一个动作构成一个音素。音素分为元音、辅音两大类。
如汉语音节 ā(啊)只有一个音素,ài(爱)有两个音素,dāi(呆)有三个音素等。
对汉语,一般用23个声母和24个韵母作为音素集。如下:

对英语,常用的音素集是卡内基梅隆大学提供的一套由39个音素构成的音素集。如下:

发音波形
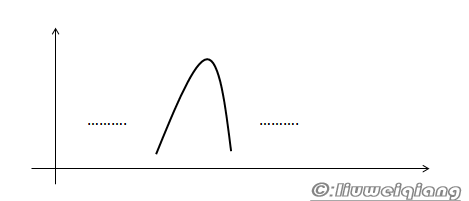
声带发出的波形大致像三角波形,如下图:
经过声腔这个天然的滤波器后就可以变成各种声音了,如下图:
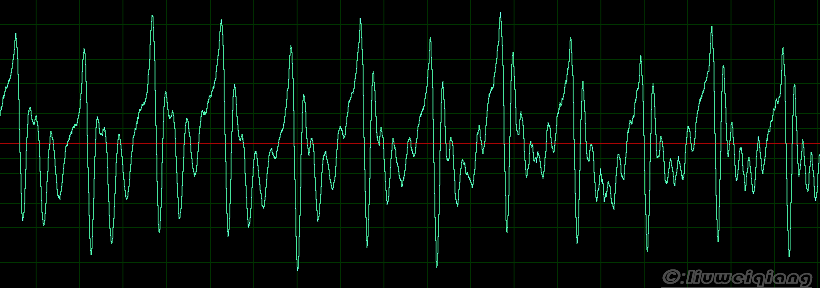
当然这个基频男女有别,一般低于165Hz为男人,高于180Hz为女人。
采样
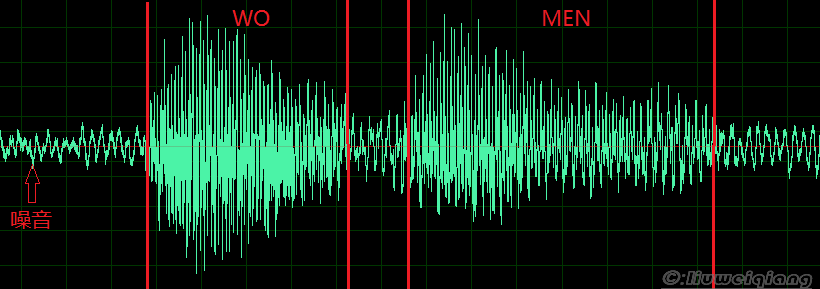
上图就是录音“我们”的离散波形图。
自然界中的声音都是连续的波形,为了使用计算机计算,我们需要使用ADC(模数转换)模块,将声音的声强变化使用二进制数来表示,当然,无论使用何种ADC模块,信号都会有些丢失。
采样是指用每隔一定时间的信号样值序列来代替原来在时间上连续的信号,也就是在时间上将模拟信号离散化。
相关术语
- 采样位数:可以理解为采集卡处理声音的解析度。这个数值越大,解析度就越高,录制和回放的声音就越真实。常用的有8 bits,16 bits等。
- 采样频率:每秒钟的采样样本数叫做采样频率。采样频率越高,数字化后声波就越接近于原来的波形,即声音的保真度越高,但量化后声音信息量的存储量也越大。常用的有8000hz,16000hz,44100hz等。
相关要求
根据采样定理,只有当采样频率高于声音信号最高频率的两倍时,才能把离散模拟信号表示的声音信号唯一地还原成原来的声音。
预加重
对于语音信号来说,语音的低频段能量较大,能量主要分布在低频段,语音的功率谱密度随频率的增高而下降,这样,信号的高频段的输出信噪比明显下降,为了修复这种状况,我们可以采用预加重技术对信号做处理。
预加重也就高通滤波,可以在分帧之前处理,那它就针对整段语音。
也可以放在分帧之后处理,先进行分帧,然后按帧预加重,这种做法比较符合实时流。
分帧加窗
假设一首歌,你用全部的数据去做频谱转换,得到的仅仅是整首歌的频率信息,而这些频率变化信息全丢失了。
也就是说,对较长信号的处理,容易丢失了时域信息。而短时的分析,能再一定程度上保留时域信息。
语音是一个短时平稳的信号,一般在10ms-30ms区间,为了获取某个频率在某个时刻有多大,我们要对语音信号加窗分帧来处理。
得到离散的音频数据后,我们就要开始拿数据来做处理了,如下图:
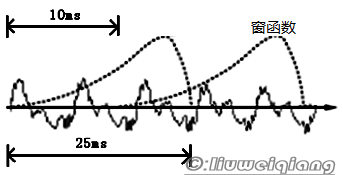
使用移动窗函数来划取每一小段,这一小段称为一帧,帧与帧之间是有交叠的。
图中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。
这里解释下为什么还要加窗,直接一段一段的截取数据分析不就行了?
其实分帧与加窗是两个不同的概念:
- 分帧:语音信号是快速变化但在短时确是平稳的(短时平稳性),而傅里叶变换适用于分析平稳的信号。一般把帧长取为20~50ms,这样一帧内既有足够多的周期,又不会变化太剧烈。
- 加窗:因为傅立叶变换对应的是无限信号,信号经过分帧后变成有限信号,分帧的信号再进行傅立叶变换后,高频部分将有”泄露”,所以要加窗。
另外,为什么帧与帧之间要有部分交叠?
由于帧与帧连接处的信号会因为加窗而被弱化,为了保留连接处的信息,因此要适当有些交叠。
至于窗函数的总类,那就多了,一般有如下几类:
- 幂窗:采用时间变量某种幂次的函数,如矩形、三角形等。
- 三角函数窗:正弦或余弦函数等组合成复合函数,例如汉宁窗、海明窗等。
- 指数窗:采用指数时间函数,例如高斯窗等。
如下是几个常用的窗函数以及他们的频率图:
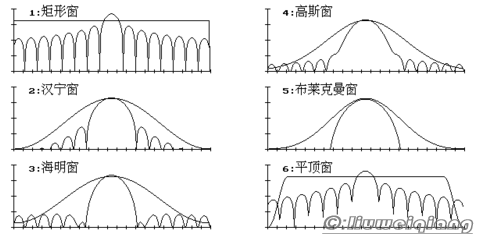
一般不加窗函数实际就默认使用了矩形窗
提取特征
得到每一帧的数据以后,由于这些数据几乎没有描述能力,因此必须把这些数据做一个转换。
声学特征有好几种:
-
线性预测系数LPCC
-
倒谱系数CEP
-
Mel倒谱系数MFCC
目前比较流行的是用Mel倒谱系数MFCC。
MFCC(梅尔倒谱系数):
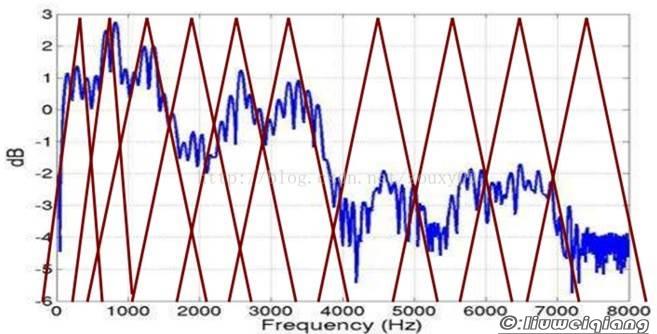
根据人耳听觉机理的研究发现,人耳对不同频率的声波有不同的听觉敏感度。
从200Hz到5000Hz的语音信号对语音的清晰度影响对大。
两个响度不等的声音作用于人耳时,则响度较高的频率成分的存在会影响到对响度较低的频率成分的感受,使其变得不易察觉,这种现象称为掩蔽效应。
由于频率较低的声音在内耳蜗基底膜上行波传递的距离大于频率较高的声音,故一般来说,低音容易掩蔽高音,而高音掩蔽低音较困难。
在低频处的声音掩蔽的临界带宽较高频要小。所以,人们从低频到高频这一段频带内按临界带宽的大小由密到疏安排一组带通滤波器,对输入信号进行滤波。
将每个带通滤波器输出的信号能量作为信号的基本特征,对此特征经过进一步处理后就可以作为语音的输入特征。
由于这种特征不依赖于信号的性质,对输入信号不做任何的假设和限制,又利用了听觉模型的研究成果。
因此,这种参数比基于声道模型的LPCC相比具有更好的鲁邦性,更符合人耳的听觉特性,而且当信噪比降低时仍然具有较好的识别性能。
人耳就像一个滤波器组:
MFCC系数的计算非常复杂,大致计算过程如下:
FFT->Mel滤波器组滤波->log对数运算->dct解卷积->倒谱提升->差分
在计算MFCC系数后,一般前几个系数特别大,后面的系数比较小,可以忽略。因此比较常用的做法是仅保留前12~20个系数作为每一帧的声学特征向量。
至此,整段音频数据就成了一个12行(假设声学特征是12维)、N列的一个矩阵,这里N为总帧数。
这样有2个好处:
- 运算量降低。
- 特征比原始语音有更好的分辨能力。
端点检测
端点检测是语音识别和语音处理的一个基本环节,也是语音识别研究的一个热点领域。技术的主要目的是从输入的语音中对语音和非语音进行区分,主要功能可以有:
- 自动打断。
- 去掉语音中的静音成分。
- 获取输入语音中有效语音。
- 去除噪声,对语音进行增强。
目前端点检测技术有基于时域、频域、模型,也有基于混合的。
常用的方法如下:
-
时域:
- 时域能量大小。 - 时域平均过零率。无声段信号变化较为缓慢, 而清音段信号在幅度上变化剧烈, 穿越零电平次数也多。 - 短时相关性分析。相关性分析主要是利用语音的相关性比噪声强,噪声之间的相关性呈现下降的趋势,但因为噪声种类太多,因此只针对少量、特定噪声。 -
频域:
- 基频。有人这样尝试,通过基频的检测,来表达声音是否真的存在,这类算法的鲁棒性很强,但对于轻音就会面临比较大的风险了。 - 谱熵。谱熵在频域与时域较量时,是比较优秀的,鲁棒性明显好于时域。 - 频域子带。这种方法对于自适应类的算法来说,是比较优秀的,因为可以通过子带选择和设计,改变噪声的估计。 -
模型:
- HMM。这个应用和语音识别一样,用分布表达语音的分布情况。 - MLP。根据频域和时域区分性特征,达到分类的效果。 - DNN。主要训练噪声模型。
就效果来说,对于一般应用,如果信噪比很高,用什么算法都可以。如果信噪比不高,基本上用什么都不是很行,在基频或模型效果可能会优于其它的算法。
语音识别
语音识别按不同的角度有以下几种分类:
从是否有停顿来说:分为孤立词语音识别、连续语音识别。
从词汇量来说:分为小词汇、中词汇、大词汇语音识别。
从音源来说:分为特定人、一般人语音识别。
识别方法
-
模板匹配法:早期小词汇,特定人,孤立词所使用的方法,原理很简单。把孤立词的声学特征放入模板库,然后识别的时候依次匹配各个模板,哪个得分最高就是哪个,常用的算法有DTW(动态时间规整法)。
-
随机参数模型法:这个是目前的主流方法,使用HMM(隐马尔科夫模型),适合非特定人,连续性语音识别,在孤立词语音识别上的识别率也比模板匹配法高,但缺点是训练数据大,训练时间长,工作内存大。
-
非参数模型矢量量化法(VQ):比HMM更少的训练时间,训练数据,而且识别时间和工作存储也更少,缺点是大词汇量的识别性能不如HMM好。
-
其它方法:例如人工智能网络(ANN) ,混合方法等。
识别过程
以连续语音识别为例子。
在这个环节需要三个模块参与:
- 声学模型:
- 语言学模型:
- 搜索算法
在小词汇、孤立词语音识别中,语言模型可以裁剪。
在此就不对语言模型进行讨论。
声学模型
声学模型一般采用隐马尔可夫模型(Hidden Markov Model,HMM),针对孤立语音识别和连续识别,模型单元也不同,可以针对音素建模,也可以针对音节或词组建模。
因为HMM模型很复杂,在此不做解释,仅仅把它当作一个模板即可。
以汉语为例子

搜索算法
语音识别需要对所有的特征向量和所有的模型做比较匹配,这是一个非常耗时的工作。
因此这里又存在很多搜索匹配的算法,比较流行的是采用Viterbi算法。
在此,这些语音信号就由模型匹配得出的最大概率而转变成语言信息。
开源框架
比较流行的开源语音识别软件有如下几种(只限可以用于嵌入式):
- CMU-Sphinx:有C语言、JAVA语言版本,可以裁剪用于嵌入式。
- HTK:C语言实现,更新很慢。
- Kaldi :C++语言实现,最近比较火。
CMU-Sphinx
官网网址: http://cmusphinx.sourceforge.net/
Pocketsphinx — 用C语言编写的轻量级识别库
Sphinxbase — Pocketsphinx所需要的支持库
Sphinx3 — 为语音识别研究用C语言编写的解码器
Sphinx4 — 为语音识别研究用JAVA语言编写的解码器
CMUclmtk — 语言模型工具
Sphinxtrain — 声学模型训练工具
下面我们分析下Sphinx能否裁剪用于嵌入式平台(目标200M主频,1M内存,8M存储)。
可用性-内存
裁剪后估计大概需要800K-1M
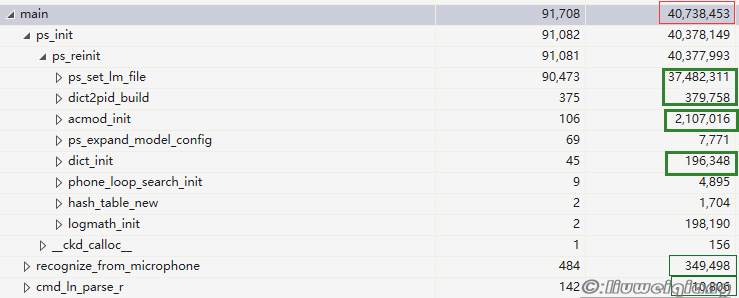
可用性-CPU
因为是在PC上跑的demo,而且demo又没有裁剪,PC和嵌入式计算平台又不具备可比性,因此这个数据没有准确的,只能估算下。
如果原封不动采用Sphinx的识别过程,个人估计200M主频不够用,因为在计算特征值环节存在大量数学运算。
除非在特征值计算方面做些裁剪或修改。
可用性-FLASH
参考一下PC的二进制文件大小,估算下大概2M大小,裁剪优化应该可以缩小些。
总结
有待验证,回头补上。

