简介
这章主要介绍RTX的链表管理,包括就绪任务的链表,延时任务的链表,等待事件,信号量,邮箱等列表,以及一个特殊FIFO队列。
关键结构
先看看task的控制块结构:
typedef struct OS_TCB {
/* General part: identical for all implementations. */
U8 cb_type; /* Control Block Type */
U8 state; /* Task state */
U8 prio; /* Execution priority */
U8 task_id; /* Task ID value for optimized TCB access */
struct OS_TCB *p_lnk; /* Link pointer for ready/sem. wait list */
struct OS_TCB *p_rlnk; /* Link pointer for sem./mbx lst backwards */
struct OS_TCB *p_dlnk; /* Link pointer for delay list */
struct OS_TCB *p_blnk; /* Link pointer for delay list backwards */
.
.
.
} *P_TCB;
以上主要列出与这节有关的字段,与任务运行以及调度有关的字段省略了。
以上部分占用1+1+1+1+4+4+4+4=20个字节。
cb_type表示控制块的类型,分以下几种
/* Values for 'cb_type' */
#define TCB 0 //代表任务控制块
#define MCB 1 //代表邮箱控制块
#define SCB 2 //代表信号量控制块
#define MUCB 3 //代表互斥量控制块
#define HCB 4 //代表链表头,在初始化时使用
还有一个结构体非常重要,因为它才是链表管理的主角:
typedef struct OS_XCB {
U8 cb_type; /* Control Block Type */
struct OS_TCB *p_lnk; /* Link pointer for ready/sem. wait list */
struct OS_TCB *p_rlnk; /* Link pointer for sem./mbx lst backwards */
struct OS_TCB *p_dlnk; /* Link pointer for delay list */
struct OS_TCB *p_blnk; /* Link pointer for delay list backwards */
U16 delta_time; /* Time until time out */
} *P_XCB;
看起来是不是和OS_TCB前面的字段很像?这里先不做解释,下文会有讲解。
来看看每个字段的意思:
-
cb_type 和OS_TCB里的一样,上面说过了
-
p_lnk 任务的链表节点
-
p_rlnk 信号量和邮箱任务的反向链表节点
-
p_dlnk 延时任务的链表节点
-
p_blnk 延时任务的反向链表节点
-
delta_time 超时时间
以上就是三个主要的结构
关键变量
由于是链表管理,因此有必要定义一个链表头,不然初始化不好处理。
/* List head of chained ready tasks */
struct OS_XCB os_rdy;
/* List head of chained delay tasks */
struct OS_XCB os_dly;
上面就是就绪任务链表头和延时任务链表头。
它们会在rt_sys_init里被初始化,如下:
/* Set up ready list: initially empty */
os_rdy.cb_type = HCB;
os_rdy.p_lnk = NULL;
/* Set up delay list: initially empty */
os_dly.cb_type = HCB;
os_dly.p_dlnk = NULL;
os_dly.p_blnk = NULL;
os_dly.delta_time = 0;
注意看cb_type为HCB(H为head的缩写)。
关键实现
rt_put_prio
先来看看第一个api,主要是链接一个任务:
/*--------------------------- rt_put_prio -----------------------------------*/
void rt_put_prio (P_XCB p_CB, P_TCB p_task) {
/* Put task identified with "p_task" into list ordered by priority. */
/* "p_CB" points to head of list; list has always an element at end with */
/* a priority less than "p_task->prio". */
P_TCB p_CB2;
U32 prio;
BOOL sem_mbx = __FALSE;// 链表头控制块是否是信号量、邮箱、互斥量标志
if (p_CB->cb_type == SCB || p_CB->cb_type == MCB || p_CB->cb_type == MUCB) {
sem_mbx = __TRUE;
}
prio = p_task->prio; //获取要插入任务的优先级
p_CB2 = p_CB->p_lnk; //获取链表头的下一个节点
/* Search for an entry in the list */
while (p_CB2 != NULL && prio <= p_CB2->prio) { //找出优先级排序恰当的位置 这里使用<=号是为了在同优先级任务起到轮询的作用,但个人觉得这里有个bug,如果重复调用rt_put_prio,参数都一样,那这里会陷入死循环。
p_CB = (P_XCB)p_CB2;
p_CB2 = p_CB2->p_lnk;
}
/* Entry found, insert the task into the list */
p_task->p_lnk = p_CB2;
p_CB->p_lnk = p_task;
if (sem_mbx) { //如果标志量为真,那么也把反向链表保存起来,这里其实就形成了一个双向链表。
if (p_CB2 != NULL) {
p_CB2->p_rlnk = p_task;
}
p_task->p_rlnk = (P_TCB)p_CB;
}
else {
p_task->p_rlnk = NULL; //不需要使用双向链表
}
}
咋一看,在while循环里p_CB = (P_XCB)p_CB2;怎么可以直接转换?别急,让我做个试验:
typedef struct OS_TCB2 {
/* General part: identical for all implementations. */
unsigned char cb_type; /* Control Block Type */
unsigned char state; /* Task state */
unsigned char prio; /* Execution priority */
unsigned char task_id; /* Task ID value for optimized TCB access */
struct OS_TCB *p_lnk; /* Link pointer for ready/sem. wait list */
struct OS_TCB *p_rlnk; /* Link pointer for sem./mbx lst backwards */
struct OS_TCB *p_dlnk; /* Link pointer for delay list */
struct OS_TCB *p_blnk;
}*P_TCB2;
typedef struct OS_XCB2 {
unsigned char cb_type; /* Control Block Type */
struct OS_TCB *p_lnk; /* Link pointer for ready/sem. wait list */
struct OS_TCB *p_rlnk; /* Link pointer for sem./mbx lst backwards */
struct OS_TCB *p_dlnk; /* Link pointer for delay list */
struct OS_TCB *p_blnk; /* Link pointer for delay list backwards */
} *P_XCB2;
int main (void) {
struct OS_TCB2 A;
struct OS_XCB2 B;
int a = sizeof(A);//调试a=20
int b = sizeof(B);//调试a=20
}
由此可以确认,cortex-m3内核是按4字节对齐方式排列的,因此p_CB = (P_XCB)p_CB2;强制类型转换是有效的。
其实这里如果多定义一个P_TCB变量来记录当前节点位置,就没必要在这里做强制转换了,这里这用做主要还是为了节省栈的使用,毕竟这是为了资源有限量身定做的系统,能省则省嘛!
其它的细节看我的注释也就能明白了,实在看不懂的就看看我下面画的图:
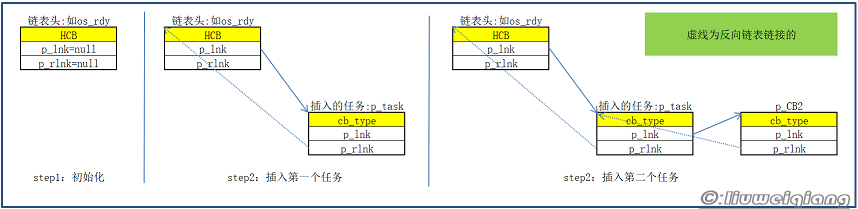
至于注释中个人认为的bug,我在keil中做过仿真,确实会陷入无限循环,只是在实际运用中,这种做法很少。
rt_get_first
因为在插入时已经排好序了,因此获取时只需获取第一个就可以。
/*--------------------------- rt_get_first ----------------------------------*/
P_TCB rt_get_first (P_XCB p_CB) {
/* Get task at head of list: it is the task with highest priority. */
/* "p_CB" points to head of list. */
P_TCB p_first;
p_first = p_CB->p_lnk;//获取链表头的第二个节点,也就是第一个任务的控制块。
p_CB->p_lnk = p_first->p_lnk;//移除第一个任务后,为了链表头有效,必须链表头链接到第二个任务控制块上。
if (p_CB->cb_type == SCB || p_CB->cb_type == MCB || p_CB->cb_type == MUCB) { //如果是双向链表,必须重新给p_lnk赋值。
if (p_first->p_lnk != NULL) {
p_first->p_lnk->p_rlnk = (P_TCB)p_CB;
p_first->p_lnk = NULL;
}
p_first->p_rlnk = NULL;
}
else {
p_first->p_lnk = NULL;
}
return (p_first);//返回第一个任务控制块。
}
rt_put_rdy_first
这个接口作用为强行把一个任务放在最先执行。
/*--------------------------- rt_put_rdy_first ------------------------------*/
void rt_put_rdy_first (P_TCB p_task) {
/* Put task identified with "p_task" at the head of the ready list. The */
/* task must have at least a priority equal to highest priority in list. */
p_task->p_lnk = os_rdy.p_lnk; //不管你优先级多少,我要最先执行
p_task->p_rlnk = NULL;
os_rdy.p_lnk = p_task;//os_rdy也是认怂,那就你先执行
}
rt_get_same_rdy_prio
获取相同优先级的任务,如果没有则返回NULL。这里只是判断os_rdy链表的第一个任务。
/*--------------------------- rt_get_same_rdy_prio --------------------------*/
P_TCB rt_get_same_rdy_prio (void) {
/* Remove a task of same priority from ready list if any exists. Other- */
/* wise return NULL. */
P_TCB p_first;
p_first = os_rdy.p_lnk;
if (p_first->prio == os_tsk.run->prio) {
os_rdy.p_lnk = os_rdy.p_lnk->p_lnk;
return (p_first);
}
return (NULL);
}
rt_rmv_list
这个就很简单了,删除一个任务,不做多解释。
/*--------------------------- rt_rmv_list -----------------------------------*/
void rt_rmv_list (P_TCB p_task) {
/* Remove task identified with "p_task" from ready, semaphore or mailbox */
/* waiting list if enqueued. */
P_TCB p_b;
if (p_task->p_rlnk != NULL) { //如果是信号量,邮箱等待链表
/* A task is enqueued in semaphore / mailbox waiting list. */
p_task->p_rlnk->p_lnk = p_task->p_lnk;
if (p_task->p_lnk != NULL) {
p_task->p_lnk->p_rlnk = p_task->p_rlnk;
}
return;
}
p_b = (P_TCB)&os_rdy; //如果是就绪任务链表
while (p_b != NULL) {
/* Search the ready list for task "p_task" */
if (p_b->p_lnk == p_task) {
p_b->p_lnk = p_task->p_lnk;
return;
}
p_b = p_b->p_lnk;
}
}
rt_resort_prio
指定为一个任务进行重排序。
/*--------------------------- rt_resort_prio --------------------------------*/
void rt_resort_prio (P_TCB p_task) {
/* Re-sort ordered lists after the priority of 'p_task' has changed. */
P_TCB p_CB;
if (p_task->p_rlnk == NULL) { //如果是放置在就绪任务链表里的话就直接给&os_rdy到p_CB。
if (p_task->state == READY) {
/* Task is chained into READY list. */
p_CB = (P_TCB)&os_rdy;
goto res;
}
}
else { //如果不是在就绪任务链表里,那就回溯到链表头。
p_CB = p_task->p_rlnk;
while (p_CB->cb_type == TCB) {
/* Find a header of this task chain list. */
p_CB = p_CB->p_rlnk;
}
res:rt_rmv_list (p_task); //直接删除任务
rt_put_prio ((P_XCB)p_CB, p_task); //再重新插入就排好序了
}
}
rt_put_dly
从这开始的连续三个接口都是使用os_dly延时链表。
/*--------------------------- rt_put_dly ------------------------------------*/
void rt_put_dly (P_TCB p_task, U16 delay) {
/* Put a task identified with "p_task" into chained delay wait list using */
/* a delay value of "delay". */
P_TCB p;
U32 delta,idelay = delay;//要延时的时间
p = (P_TCB)&os_dly;
if (p->p_dlnk == NULL) { //如果是第一个延时任务
/* Delay list empty */
delta = 0;
goto last;
}
delta = os_dly.delta_time;
while (delta < idelay) {//找到要延时的任务放置的位置。
if (p->p_dlnk == NULL) {//如果循环完链表还没找到合适的位置,那直接放置在链表末尾。
/* End of list found */
last: p_task->p_dlnk = NULL;
p->p_dlnk = p_task;
p_task->p_blnk = p;
p->delta_time = (U16)(idelay - delta);//填写任务需要延时时间减去整个链表延时的时间,这样任务就能依次按序延时执行。
p_task->delta_time = 0;
return;
}
p = p->p_dlnk;
delta += p->delta_time;//累加以遍历的任务延时时间
}
/* Right place found */
p_task->p_dlnk = p->p_dlnk;
p->p_dlnk = p_task;
p_task->p_blnk = p;
if (p_task->p_dlnk != NULL) {//如果是双向链表,记得把前指针给到位。
p_task->p_dlnk->p_blnk = p_task;
}
p_task->delta_time = (U16)(delta - idelay);//找到合适位置后,就把目前已搜索的链表延时总时间减去任务需要延时的时间,为什么要减,因为我确实只需要idelay延时啊,任务自己保存的时间其实是给下一任务使用的。
p->delta_time -= p_task->delta_time;//既然多链接了一个延时任务,相当于插队了,为了避免后面的任务没有埋怨,当然自己要减去一些时间,这样对后面的链表来说,等待时间是一样的。
}
其实这个延时链表模式和我们常用的循环定时任务一样,都是使用每个链表节点代表一个延时单元,或者叫时间片段,任务之前的时间片段相加,就代表这个任务延时多少执行。
这个和rt_timer的运行模式是一样的,只不过rt_timer是在非RTOS环境在运行的,一般简单的单片机程序就可以使用这种模式。
rt_dec_dly
有了添加延时任务的接口,当然需要执行延时任务的接口了:
/*--------------------------- rt_dec_dly ------------------------------------*/
void rt_dec_dly (void) {
/* Decrement delta time of list head: remove tasks having a value of zero.*/
P_TCB p_rdy;
if (os_dly.p_dlnk == NULL) {//如果是空的延时链表
return;
}
os_dly.delta_time--;//每次只减1
while ((os_dly.delta_time == 0) && (os_dly.p_dlnk != NULL)) {//链表的第一个任务延时完毕。
p_rdy = os_dly.p_dlnk;
if (p_rdy->p_rlnk != NULL) {//如果是等待信号量、邮箱等延时的任务,等待时间一到,这里变会执行,从等待链表中删去。
/* Task is really enqueued, remove task from semaphore/mailbox */
/* timeout waiting list. */
p_rdy->p_rlnk->p_lnk = p_rdy->p_lnk;
if (p_rdy->p_lnk != NULL) {
p_rdy->p_lnk->p_rlnk = p_rdy->p_rlnk;
p_rdy->p_lnk = NULL;
}
p_rdy->p_rlnk = NULL;
}
rt_put_prio (&os_rdy, p_rdy);//把延时完毕的任务重新扔进就绪队列去排序。
os_dly.delta_time = p_rdy->delta_time;//更新链表头的延时时间,因为每次都是使用表头的时间自减。
if (p_rdy->state == WAIT_ITV) {//如果是周期性延时任务的话。
/* Calculate the next time for interval wait. */
p_rdy->delta_time = p_rdy->interval_time + (U16)os_time;//这里+ (U16)os_time 暂时不可理解,后续再来研究。
}
p_rdy->state = READY;//任务状态更新为就绪
os_dly.p_dlnk = p_rdy->p_dlnk;
if (p_rdy->p_dlnk != NULL) {
p_rdy->p_dlnk->p_blnk = (P_TCB)&os_dly;
p_rdy->p_dlnk = NULL;
}
p_rdy->p_blnk = NULL;
}
}
rt_rmv_dly
延时任务删除很简单:
/*--------------------------- rt_rmv_dly ------------------------------------*/
void rt_rmv_dly (P_TCB p_task) {
/* Remove task identified with "p_task" from delay list if enqueued. */
P_TCB p_b;
p_b = p_task->p_blnk;//因为有反向指针,可以直接找到前一个延时任务
if (p_b != NULL) {
/* Task is really enqueued */
p_b->p_dlnk = p_task->p_dlnk;
if (p_task->p_dlnk != NULL) {
/* 'p_task' is in the middle of list */
p_b->delta_time += p_task->delta_time;//直接把前一个任务的延时时间加上要删除的延时任务时间就可以了,保证了之后的任务的延时时间总和不变。
p_task->p_dlnk->p_blnk = p_b;
p_task->p_dlnk = NULL;
}
else {
/* 'p_task' is at the end of list */
p_b->delta_time = 0;
}
p_task->p_blnk = NULL;
}
}
特殊接口 rt_psq_enq
这个并不是针对os_rdy、os_dly或信号量,邮箱等链表。
这个是用于在中断服务里,不能操作事件,信号量,邮箱,就使用这个接口把操作保存进一个fifo队列,然后在PendSV_Handler里面慢慢处理之前的操作。
为了分析这个接口,我们先看看rt_inc_qi函数,顺便把os_fifo、OS_PSQ等也放在一起看:
typedef struct OS_PSFE { /* Post Service Fifo Entry */
void *id; /* Object Identification */
U32 arg; /* Object Argument */
} *P_PSFE;
typedef struct OS_PSQ { /* Post Service Queue */
U8 first; /* FIFO Head Index */
U8 last; /* FIFO Tail Index */
U8 count; /* Number of stored items in FIFO */
U8 size; /* FIFO Size */
struct OS_PSFE q[1]; /* FIFO Content */
} *P_PSQ;
#ifndef OS_FIFOSZ
#define OS_FIFOSZ 16
#endif
/* Fifo Queue buffer for ISR requests.*/
uint32_t os_fifo[OS_FIFOSZ*2+1];
uint8_t const os_fifo_size = OS_FIFOSZ;
#define os_psq ((P_PSQ)&os_fifo)
这里很多人会好奇,为什么os_fifo的占用内存为OS_FIFOSZ*2+1,+1是怎么来的,其实这个看OS_PSQ结构体就知道了,因为OS_FIFOSZ=16,而且每个队列单元OS_PSFE占用2个4字节。
因此OS_FIFOSZ2可以理解,然后又因为在OS_PSQ里first、last、count、size各占用1各字节,因此加起来就4个字节,所以会有OS_FIFOSZ2+1。
再来看看rt_inc_qi函数:
__inline static U32 rt_inc_qi (U32 size, U8 *count, U8 *first) {
U32 cnt,c2;
#ifdef __USE_EXCLUSIVE_ACCESS
do {
if ((cnt = __ldrex(count)) == size) {
__clrex();
return (cnt); }
} while (__strex(cnt+1, count));
do {
c2 = (cnt = __ldrex(first)) + 1;
if (c2 == size) c2 = 0;
} while (__strex(c2, first));
#else //我们使用非高级访问模式
__disable_irq();//关中断
if ((cnt = *count) < size) {//如果fifo队列已使用的数量小于分配数量。
*count = cnt+1;//使用数量先+1。
c2 = (cnt = *first) + 1;//使用单元移动一格。
if (c2 == size) c2 = 0;//如果超出内存,则循环到0单元。当然0单元的信息会被覆盖。
*first = c2; //更新当前头指针。
}
__enable_irq ();//开中断
#endif
return (cnt);
}
现在再来看rt_psq_enq函数就很简单了:
/*--------------------------- rt_psq_enq ------------------------------------*/
void rt_psq_enq (OS_ID entry, U32 arg) {
/* Insert post service request "entry" into ps-queue. */
U32 idx;
idx = rt_inc_qi (os_psq->size, &os_psq->count, &os_psq->first);
if (idx < os_psq->size) {
os_psq->q[idx].id = entry;//一般保存事件,信号量,邮箱等地址。
os_psq->q[idx].arg = arg;//保存附带的参数。
}
else {
os_error (OS_ERR_FIFO_OVF);
}
}
这个接口就是在中断时调用,保存要处理的事件,信号量,邮箱等操作,相当于延时到PendSV_Handler中断服务程序中处理,最大支持保存16个操作。
再来看看使用场景,在PendSV_Handler中断服务程序中,第一条指令就是BL __cpp(rt_pop_req):
/*--------------------------- rt_pop_req ------------------------------------*/
void rt_pop_req (void) {
/* Process an ISR post service requests. */
struct OS_XCB *p_CB;
P_TCB next;
U32 idx;
os_tsk.run->state = READY;
rt_put_rdy_first (os_tsk.run);
idx = os_psq->last;
while (os_psq->count) {
p_CB = os_psq->q[idx].id;
if (p_CB->cb_type == TCB) {
/* Is of TCB type */
rt_evt_psh ((P_TCB)p_CB, (U16)os_psq->q[idx].arg);//处理中断里保存的事件
}
else if (p_CB->cb_type == MCB) {
/* Is of MCB type */
rt_mbx_psh ((P_MCB)p_CB, (void *)os_psq->q[idx].arg);//处理中断里保存的邮箱
}
else {
/* Must be of SCB type */
rt_sem_psh ((P_SCB)p_CB);//处理中断里保存的信号量
}
if (++idx == os_psq->size) idx = 0;
rt_dec (&os_psq->count);
}
os_psq->last = idx;
next = rt_get_first (&os_rdy);
rt_switch_req (next);
}

